目录
今年随着自动驾驶/辅助驾驶竞争进入到深水区,各家企业都开始争相跟随特斯拉转向端到端的技术栈,而前两天看到对任少卿的采访1,也有颇多感触。从毕业以来,自己做端到端和大模型也有阵时日了,对自动驾驶这个问题有了新的理解,但也有一些以前的观点变得更坚定了。
我不太有精力去细细介绍端到端是什么,因此本文的目标受众是相关从业者,还请见谅。不过也希望这篇文章能让从业者们有所收获~
这是我开博客以来第一篇关于我自己从事行业的文章,也是时隔一年半以来博客难得的更新(真的太忙了。。),希望后面还是定期的能整理一些自己的思考在博客里吧。
端到端的前世今生
为什么要端到端?
谈论任何一个变动、改革,还是得从其原因开始谈起 (又想起导师的谆谆教诲了)。所谓端到端,就是说一个事从头到尾是由一个人/一个模型负责的。而在自动驾驶领域通常的语境下,指的则是整个自动驾驶模型是由一个完整的神经网络构成的,并且这个网络的输入端为传感器原始信息,输出端为车辆的控制信号。
被省略的一些细节
转向端到端,大家最常听到的原因是“上限更高了”。各大发布会上高管们都会说到使用端到端的好处是,端到端模型可以利用海量数据的学习不断地提升能力,而以往的堆工程师的手段,在做到某个程度之后就很难再进一步改进了,因为会有复杂系统牵一发而动全身的问题。
端到端能行吗?
但我一直有怀疑的是,端到端真的能行吗?还记得本科那会刚开始入门自动驾驶的时候,有两篇经典的神经网络控车的论文:一篇是英伟达的端到端自动驾驶开山之作CNN开车2,另一篇是Waymo的ChauffeurNet3。这两篇论文都是很彻底的基于模仿学习的神经网络控车,在今天的视角看来也无疑是纯粹的端到端架构。但是那个时候,几乎没有人能看好纯神经网络路线的未来,英伟达的控车demo也并不惊艳,尔后的几年学术界很快也不再提神经网络控车了。
—— 直到我们众所周知的由特斯拉和UniAD重新掀起的热潮。这时不禁我们又要问了,为什么端到端他又能了呢?任少卿在采访里给的解释是以前的模型能力比较弱,效果差达不到要求,只能按流水线的方式把他们排起来,等能力强了之后再一个个集成、降本,就像是工厂为什么从部件铸造+焊接转向了一体式压铸,就是因为生产工艺进步到这个地步了,而一体式压铸能带来更好的成本和材料强度。
有利肯定也有弊
我对任少卿的观点基本认同,但是我还想补充一个观点:除了模型能力、算力的提升,以前自动驾驶系统里的“规则”其实也是帮助了神经网络的演变。最早期为什么自驾领域的模型都很专一,一个很大的因素是学术界、业界的数据集定义的真值都很单一,并且需要大量的人工标注。而后来渐渐的,一个训练好的神经网络,加上一些规则的后处理,开始能够给出很高质量的结果了(虽然这个模型可能很大,后处理可能很繁重),那这样的一个神经网络 + 后处理的系统就能够用来做自动标注,生成我们所谓的“伪标签”。而自动标注系统的演进就是一个模型能力提升 → 规则后处理改进 → 整体标注质量提升 → 用更好的伪标签训更好的模型,这样一个正反馈的循环。这里面其实规则是很关键的,如果没有规则后处理在里面,那这个循环就变成了左脚踩右脚原地登天,不合逻辑了,人工规则在其中其实就起到了引入人类经验的作用,只是这个作用不是直接作用在模型上,而是作用在数据上。回到为什么端到端模型现在变得可行了,我认为一个很大的原因也是因为有了很多模块的自动标注能力的积累,我们获取很多数据标注的成本在不断降低,这才使得(基于模仿学习的)端到端自动驾驶离工程落地越来越近了。
数据驱动与规则驱动
定义数据驱动
一般而言,解决基于机器学习的模型范式被称为数据驱动,而人工用规则构建的模型在这个领域一般被成为rule-based,为了对称我就把它称为规则驱动吧。在控制领域,数据驱动的模型一般有两种训练方法:模仿学习和强化学习,前者更贴近数据驱动的灵魂 —— 有多少数据我就用多少数据,而后者则依赖一个仿真器来构造数据,算是差别比较大的另一种范式。但由于逼真的仿真器很难构造,因此强化学习在自动驾驶领域应用困难。
逆强化学习
还有一类范式叫逆强化学习,它本质上也是一种模仿学习,只是学习的对象从模型权重变成了cost function。对这个方向感兴趣的读者可以读读这两篇文章:一篇是经典的驾驶员风格建模的工作1、另一篇是IROS 2024里利用模仿学习 + InverseRL建模驾驶员风格的工作2。
Schwarting, W. et. al. (2019). Social behavior for autonomous vehicles. Proceedings of the National Academy of Sciences, 116(50), 24972-24978. ↩︎
Lin, F. et. al. (2024). PP-TIL: Personalized Planning for Autonomous Driving with Instance-based Transfer Imitation Learning. arXiv preprint arXiv:2407.18569. ↩︎
而在数据驱动的模型中,在我读本科那会,还有很多别的机器学习模型,比如在课上基本会学到的SVM、Boosting之类的,或者带概率的Gaussian过程、Bayesian网络,或者HMM、CRF等。但是众所周知,在CNN屠杀计算机视觉领域之后,(至少在自动驾驶领域)数据驱动的模型基本都是基于神经网络的了。因此在后文中,数据驱动的模型默认指的是使用模仿学习训练的神经网络,而我讨论的对象——端到端——也指的是端到端神经网络模型。
数据驱动的强项
那么现在我想来聊聊数据驱动的利与弊(以自动驾驶的视角)。数据驱动为什么受人追捧,并且也确实好用,大概有以下几点主要原因:
- 深度学习模型能有效利用数据,使得代码非常简单,系统的工程复杂性低;并且模型提升的路径清晰,只需要怼高质量的数据就行了。
- 相比于规则驱动的模型,数据驱动的模型对噪音部分鲁棒。这可能是因为在规则系统中加入不确定性的估计,会使得状态方程变得复杂,并且无法避免地要对噪音的分布做出假设(而且经常是很简陋的Gaussian)。
但是数据驱动也有一些难以忽视的弱点,除了广为人知的不可解释性之外,还有:
- 模型性能没有保障,会犯低级错误。而规则是可以符号化地证明它的正确性和适用范围的。
- 无法建模因果性、或者说构建因果关系的效率低。而规则则是一种将人类所建立的逻辑应用到一个系统相当高效的方式。(这里的效率指的是对数据和计算资源的消耗)
我关于因果性的一些理解:
- 如何确立因果性 —— 需要对照试验,这个很难,并且目前主流的模仿学习工作并不太关注这个。(Contrasting Learning是个好东西,但是在自动驾驶领域目前并没有很惊艳的效果,可能是探索不足)
- 人的规则为什么work —— 因为人建模了因果,并且这些因果可以以规则的形式固化进系统了。
- 如果因果不行,那什么地方机器可能比人做的好?—— 感知能力以及控制能力,但是中间对世界的建模不太行。
- 建模世界为什么难 —— 因为有很多 不可观 的变量。直接的例如盲区,间接的例如不同驾驶员(包括自车、他车)的驾驶风格、驾驶目的,再比如一些人也无法理解的因素,例如突然出现的动物等。这也是为什么会需要对噪音/不确定性的建模 —— 说到底这个世界只有很小的一部分是对我们来说可观测的。
因此我认为模仿学习很难建模因果性,因为很难隔离出来哪些因素可观,哪些因素不可观。如果没有因果性的建模,那数据驱动的模型还是无法逃脱其拟合一个 映射 的本质(也就是说模型学习的还是从一个集合到另一个集合某种误差最小的映射方式,而不是符号化的“知识”或者“逻辑”),这会带来泛化性弱和数据利用率低下的两大问题。
一些经验
数据驱动的上限与下限
如前文所说,一种流行的观点是数据驱动的路线上限高。但是上限高是多高呢?以及到底需要什么成本的?在数学里同样是无上界的函数,但就是能排出来一个发散速度的高低,因此我们还是要对达到这个上限的成本进行判断。可能你们见过下面这张图(by Jeff Dean)或者类似的图:
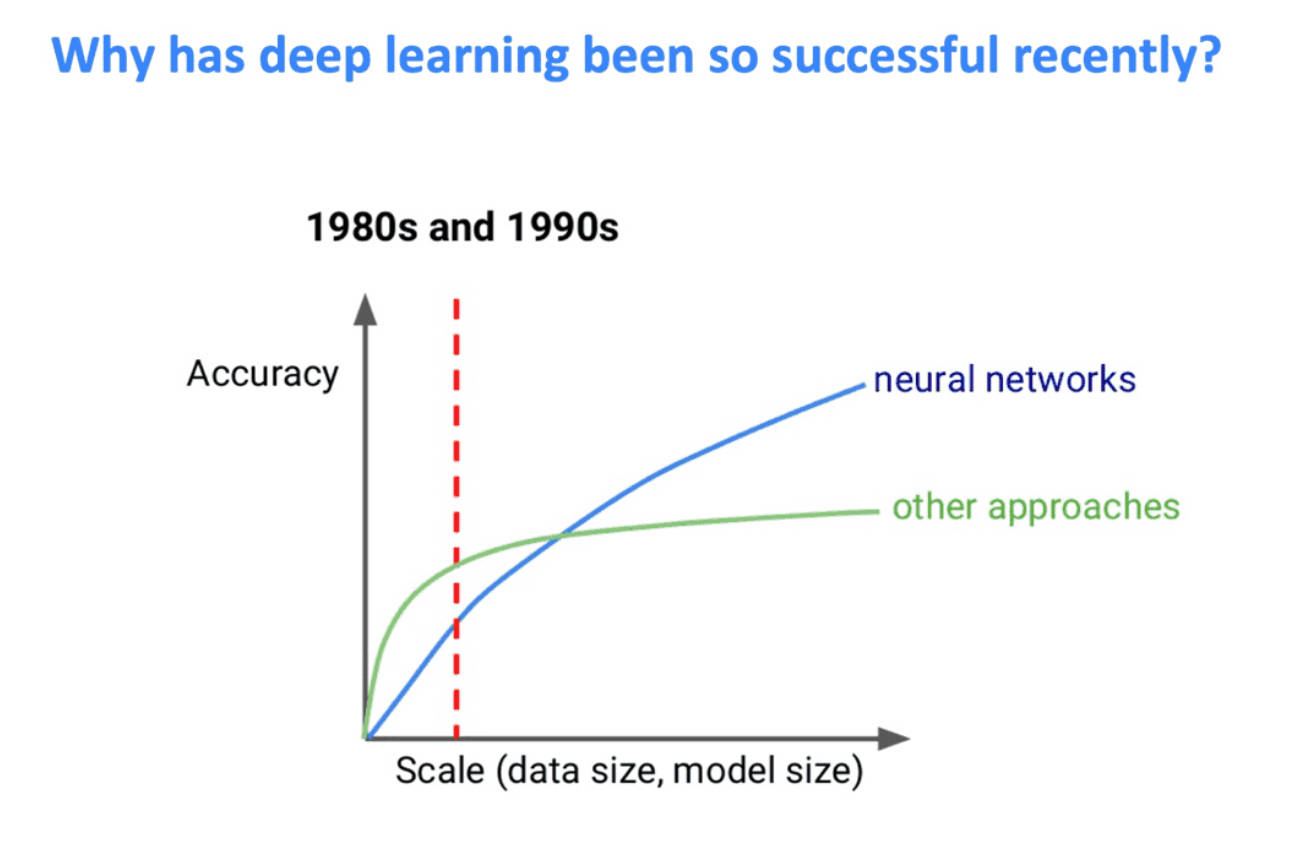
对于自动驾驶来说,可能里面的“other approaches”就是规则驱动或者部分规则驱动的模型。但是这个图的横轴是“Scale”,以前我对scale的理解并不深,现在大模型风潮吹起来之后我逐渐明白了,scale up意味着模型大小和使用的数据要同步增大。但是这在自动驾驶上是有一个巨大的问题:自动驾驶车端能部署的硬件能力是受限的,并且迭代很慢。因此对于自动驾驶而言这个曲线可能长这样:
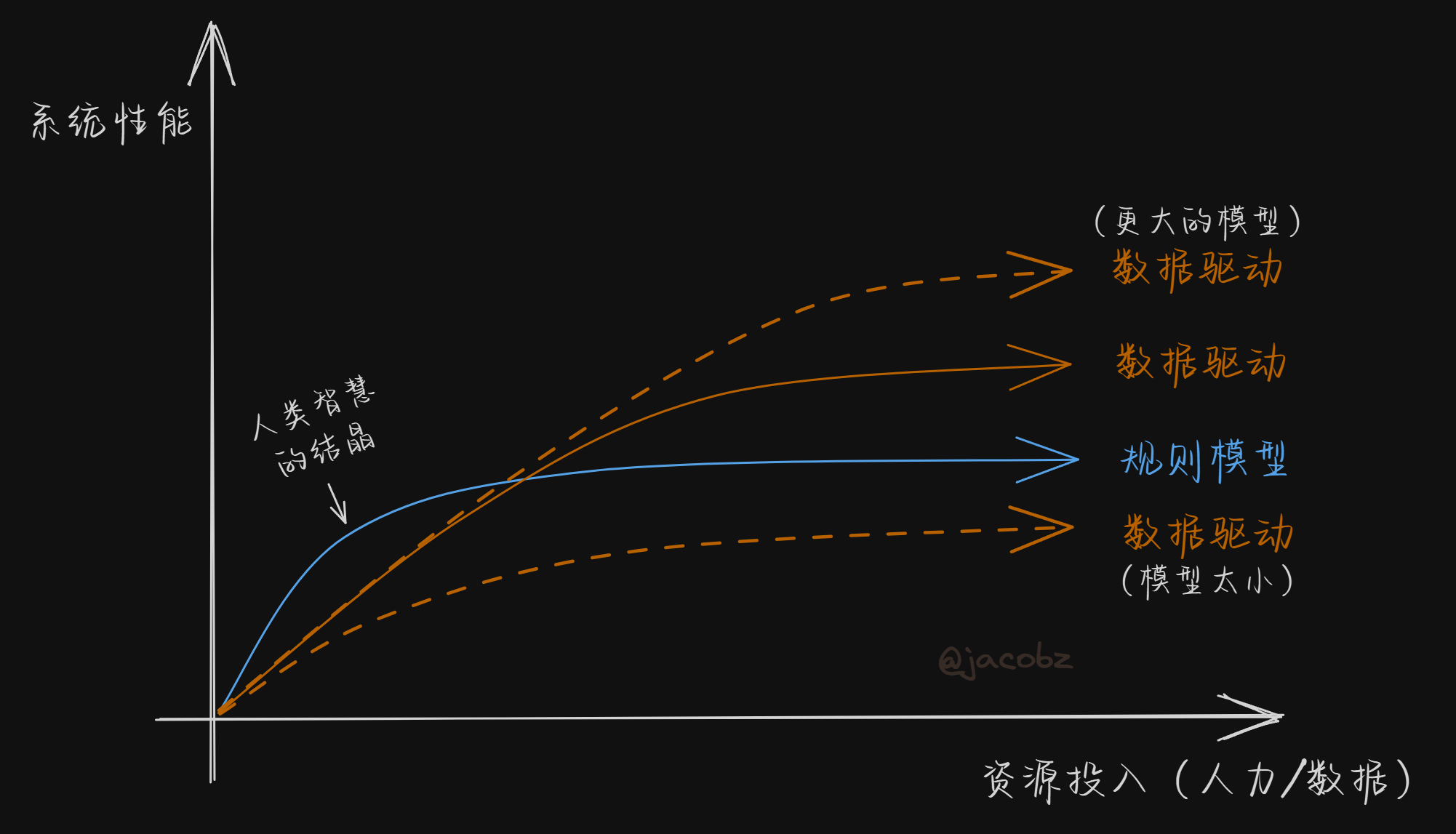
有三个值得说明的地方:
- 数据驱动的曲线在scale up之后,坡度可能没有之前那张图那么乐观,
- 图中纵轴是线性坐标系,但横轴不一定。对于规则驱动的模型来说可能是线性的(因为人力堆起来很难),但对数据驱动的模型来说可能是对数的!如果参考一些大模型scaling law的图,你会发现他们的图大多是对数或者双对数坐标系。因此对于数据驱动模型来说,边际效应可能是比规则模型更明显的。
- 这个图里系统性能一般指平均性能,但如果评价最坏性能/性能下界的,那可能又是另一个故事了。
以现在业界的车端算力水平(几百TOPS),我们是处于最上面那根线,还是最下面那根线?大部分人可能认为是中间那根橙色的线,但没有人有确切答案。以我的经验来看,在初期你会发现数据甜蜜地让人上瘾,但到了后面大数据也不是万金油了,你会碰到各种数据平衡、cost平衡的问题,除非你继续氪金上更大的模型。因此“数据驱动的模型上限高”这句话固然可能没错,但我觉得他也不是最终的end-game解决方案。
一些脑洞
不过我还想补充一个思考:
数据驱动的模型下限低,有可能是因为我们是站在人类能理解的范畴内去评价的。神经网络为什么好使,一个CNN发展早期的解释是,神经网络能够提取出一些不一样的“隐层”特征,这些特征和人们所编写的HOG特征或者Canny特征是差别很大的。神经网络没有人类给他限制的条条框框,能用自己的解题方法去解决一个问题。那么进一步想的话,是不是我们也不能完全按照人类的思维去评价这个车开的好和坏?就像一道压轴题,数据驱动的模型给出了他自己的思路里80%的步骤,人类给出了人能读懂的80%的步骤,但是由于我们看不懂模型的思路,看不懂它缺了的那20%是什么意思,我们可能就认为它“下限低”。也许在它自己的视角、自己的评价体系来看,规则驱动的模型比它下限还低呢?
那么,前途在哪
最近另外两个很火的东西 —— 大模型和世界模型 —— 他们又能改变这些吗?这里我谈谈我浅薄的认知,欢迎指正!
世界模型:无他,唯数据多尔
为什么世界模型火了,因为酷炫!哈哈哈这是我的心里话,但理性的分析可能是因为世界模型的训练不需要依赖标注。就如任少卿在采访里所说,以前的机器学习依赖标注,后来渐渐发展成了自动标注,但最理想的还是,有多少数据过来我都能用,不需要人工标注。这样的范式有两个关键词:1. 预测下一个token —— 这是大语言模型用的方法;2. 预测下一帧 —— 这就是世界模型的范式。
关于世界模型还有一些细分,一个是原来提出世界模型的人们所期望的:这个模型能听从我的控制,给出不同的输入能给出不同的世界演变;另一个是最近火起来的世界模型:我不关注输入的信息有哪些,我只想让模型能够输出我想要的下一帧就好了。但回归到数据驱动的本质上,世界模型的主要价值还是在于它能够以更高的效率去利用数据,消费数据。不过,这也意味着它跟其他数据驱动的模型相比,并没有解决上文提到的重要劣势。
大模型能成为补全自动驾驶蓝图的最后一块拼图吗?
本文的大模型特指基于有语言模态的,经过大量文本训练的大模型。喜欢“端到端大模型”这个词的读者,to be honest,这个词只是个噱头。
大模型则不一样,我对大模型在自动驾驶领域应用的态度更乐观一点。因为我认为做成自动驾驶(L4/L5)和做出来通用人工智能已经差的不远了,而大模型确实是目前朝着通用人工智能走得最远的尝试。抛开大模型上车的成本问题,它给数据驱动的范式带来的一个重要变化是:它能够用上互联网上的数据了,尤其是互联网上的语料。语言是一种高度抽象的数据表现形式,学好语言本身就是学会了一种更抽象的表征。此外,语言的另一个好处是我们能搜集到很多包含因果关系的语料,或者说人们习惯于用语言来表达因果关系(而不是通过视觉模态——例如画画,或者其他模态)。因此尽管大模型可能本质上还是一个映射,但是它能够训进去很多与因果关系相关的数据,这已经是与其他数据驱动方法很不一样的地方了。
但是大模型能搞定自动驾驶吗?恐怕还是不行的,因为它说到底还是模仿学习,还是需要数据,还是很难处理分布外的输入。更别说按照现在的趋势发展下去,大模型要有多大才够用呢。
结论
说了这么大一通,抱歉思维有点凌乱,以及有些想讲的东西在写的过程中就忘掉了。。但我的这些思考最后收束到的观点是:
纯粹的端到端很难解决好自动驾驶这个问题。如何将数据驱动的模型与人类的规则更好地结合起来,仍然是有价值的,并且是需要探索的。
一种可能的未来是,端到端模型出到一种很简明的,带高层意图以及不确定性的显式表征,而后规则模型基于这个表征加一些经典高效的算法(例如MCTS)给出一个数值性能优异,满足各种约束和cost偏好的轨迹,交给鲁棒控制模型控车。如果五年或者十年后,完成L4/L5的模型是这样的一套架构,那我认为我会非常放心地将方向盘交给AI,不然你懂的,“越是了解就越是敬畏”的谚语对我而言在自动驾驶系统上也是仍然成立的。
Bojarski, M. et. al. (2016). End to end learning for self-driving cars. arXiv preprint arXiv:1604.07316. ↩︎
Bansal, M. et. al. (2018). Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. arXiv preprint arXiv:1812.03079. ↩︎